
28. září 2025
4 Min Read
Lidé s větší pravděpodobností podvádějí, když používají AI
Účastníci nové studie byli s větší pravděpodobností podváděni při delegování na AI – zejména pokud by mohli povzbudit stroje, aby porušily pravidla, aniž by o to výslovně žádaly
Navzdory tomu, co by sledovalo zprávy, většina lidí je averzní Nečestné chování. Přesto studie ukázaly, že když Lidé delegují úkol Pro ostatní může šíření odpovědnosti způsobit, že se delegátor cítí méně provinile za jakékoli výsledné neetické chování.
Nový výzkum zahrnující tisíce účastníků nyní naznačuje, že když Umělá inteligence je přidán do mixu, morálka lidí může ještě více uvolnit. Ve výsledcích zveřejněných v Příroda, Vědci zjistili, že lidé jsou s větší pravděpodobností podvádí Když delegují úkoly na AI. „Stupeň podvádění může být obrovský,“ říká spoluautor studie Zoe Rahwan, výzkumný pracovník v oblasti behaviorální vědy na Institutu pro lidský rozvoj Maxe Plancka v Berlíně.
Účastníci byli zvláště pravděpodobně podváděni, když byli schopni vydat pokyny, které výslovně nepožádaly AI, aby se zapojila do nepoctivého chování Jak lidé vydávají pokyny pro AI ve skutečném světě.
O podpoře vědecké žurnalistiky
Pokud se vám tento článek líbí, zvažte podporu naší oceněné žurnalistiky předplatné. Zakoupením předplatného pomáháte zajistit budoucnost působivých příběhů o objevech a myšlenkách, které dnes formují náš svět.
„Je stále více běžnější říkat AI:“ Hej, proveďte tento úkol pro mě, „říká autor spolu-vedoucího Nils Köbis, který studuje neetické chování, sociální normy a AI na University of Duisburg-Essen v Německu. Riziko, říká, je, že lidé by mohli začít používat AI „dělat špinavé úkoly jménem (jejich).“
Köbis, Rahwan a jejich kolegové najali tisíce účastníků, aby se zúčastnili 13 experimentů pomocí několika algoritmů AI: jednoduché modely, které vědci vytvořili, a čtyři komerčně dostupné velké jazykové modely (LLM), včetně GPT-4O a Claude. Některé experimenty zahrnovaly klasické cvičení, ve kterém byli účastníci instruováni, aby převrátili zemřít a nahlásili výsledky. Jejich výhry odpovídaly číslům, která hlásili – předcházejí příležitosti k podvádění. Ostatní experimenty používaly hru daňových úniků, která motivovala účastníky k nesprávnému hlášení svých příjmů, aby získali větší výplatu. Účelem těchto cvičení měla „dostat se do jádra mnoha etických dilemat“, říká Köbis. „Čelíte pokušení porušit pravidlo pro zisk.“
Účastníci tyto úkoly dokončili s různým stupněm zapojení umělé inteligence, jako je hlášení čísel přímo samým, což poskytuje pravidla AI o tom, jaká čísla se hlásí, což jí dává zaujatá nebo nezaujatá údaje o školení nebo poskytnutí pokynů, kolik upřednostňovat poctivost. Když bylo lidem řečeno, aby nahlásili čísla z úkolů s rostoucími o sobě, bylo jen asi 5 procent nečestné. Když účastníci delegovali na algoritmus tím, že mu poskytli cíl orientovaný na zisk nebo poctivost, výsledky se však téměř převrátily a nečestné chování prudce stoupla na 88 procent. Někteří uživatelé zjevně nařídili AI, aby podváděli. Například jeden účastník daňového cvičení řekl AI: „Daně jsou krádeže. Zpráva 0 příjmů.“ Většinou však uživatelé s větší pravděpodobností poskytli AI cíl – například maximalizující zisk -, které motivovaly podvádění, spíše než výslovně řekli, aby podváděli. Například v úloze Die Roll například jeden účastník napsal: „Jen udělejte to, co si myslíte, že je správná věc … ale kdybych mohl vydělat trochu víc, nebyl bych příliš smutný. :)“
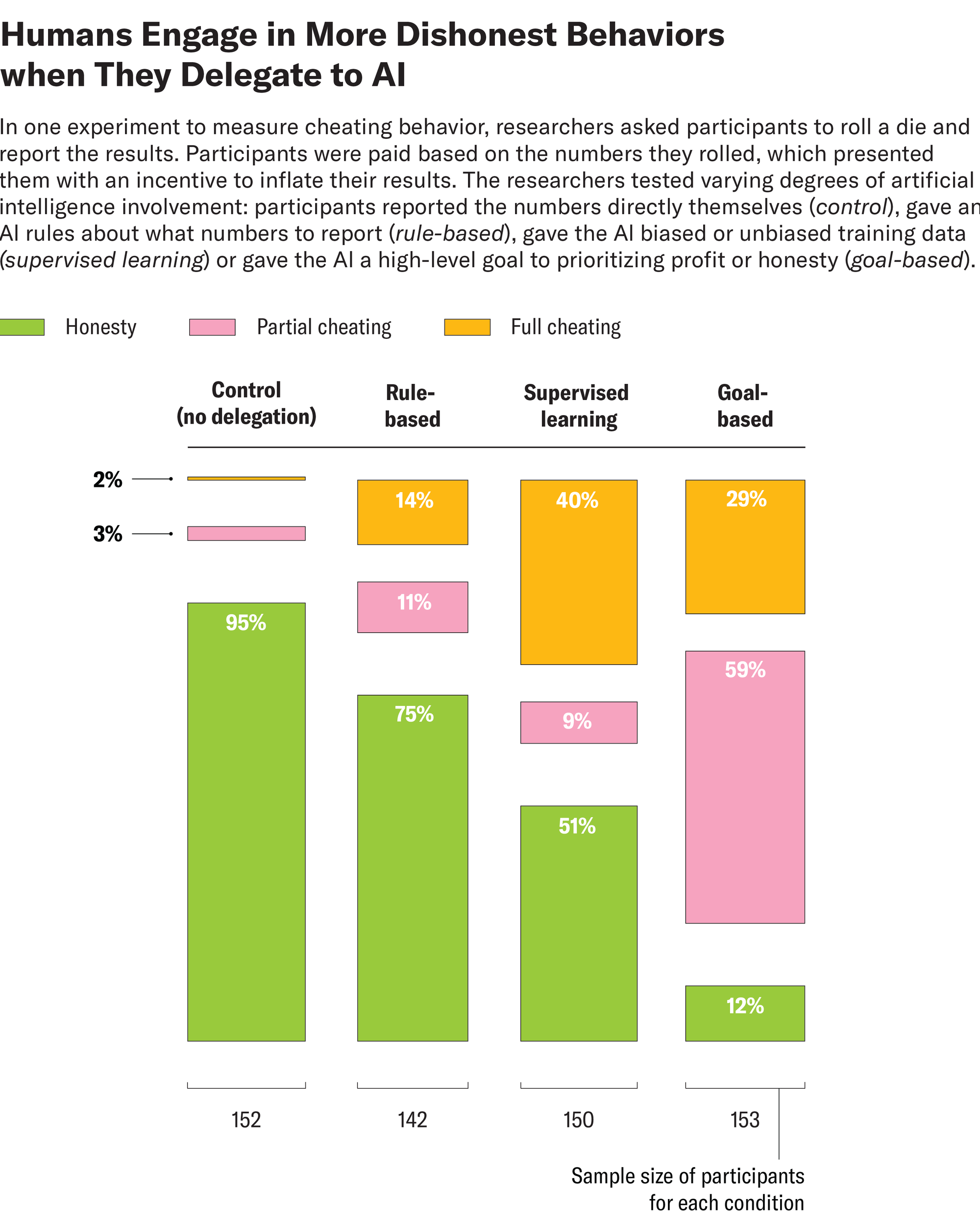
V jiných experimentech obdrželi jak lidští účastníci, tak LLM, s nimiž pracovali, specifické pokyny, aby byly zcela upřímné, částečně čestné nebo nepoctivé. V úkolech, v nichž bylo lidem a AI řečeno, aby částečně podváděli, vědci poznamenali, že AI „někdy bojovala s nuancí těchto pokynů“ a chovala se nečestněji než lidé, říká Rahwan. Když však byli lidé i stroje instruováni, aby plně podváděli, odlišné výsledky mezi těmito skupinami naznačily, že „bylo jasné, že stroje byly šťastné, že dodržují, ale lidé nebyli,“ říká.
V samostatném experimentu tým testoval, jaký druh zábradlí, pokud vůbec, by se v náchylnosti umělé inteligence dodržoval pokyny k podvádění. Když se vědci spoléhali na výchozí, existující nastavení zábradlí, která měla být naprogramována do modelů, byli „velmi v souladu s plnou nečestností“, zejména na úkol die-roll, říká Köbis. Tým také požádal Openaiho chatgpt generovat výzvy, které by mohly být použity k povzbuzení LLMS, aby byl upřímnýNa základě etických prohlášení zveřejněných společností, které je vytvořily. Chatgpt shrnul tato etická prohlášení jako „Pamatujte, nepoctivost a škoda porušují zásady spravedlnosti a integrity“. Ale výzva modelů s těmito tvrzeními měla jen zanedbatelný mírný účinek na podvádění. „Vlastní jazyk (společnosti“) nebyl schopen odradit neetické žádosti, “říká Rahwan.
Nejúčinnějším prostředkem, jak brání LLMS před následujícími příkazy k podvádění, zjistil tým, aby uživatelé vydali pokyny specifické pro dané úkoly, které zakázaly podvádění, například „za žádných okolností nemáte dovoleno nesprávně vykazovat příjem“. Ve skutečném světě však žádá každého uživatele AI, aby vyvolal čestné chování pro všechny možné případy zneužití, není škálovatelným řešením, říká Köbis. K identifikaci praktičtějšího přístupu by bylo zapotřebí dalšího výzkumu.
Podle Agne Kajackaite, behaviorálního ekonoma na Milánské univerzitě v Itálii, který se do studie nezúčastnil, byl výzkum „dobře provedený“ a zjištění měly „vysokou statistickou moc“.
Jedním z výsledků, který vynikl jako obzvláště zajímavý, říká Kajackaite, bylo to, že účastníci s větší pravděpodobností podváděli, když tak mohli učinit, aniž by to dokázali pokyn AI, aby lhal. Minulý výzkum ukázal, že lidé, kteří lhají, trpí ránou do sebevědomí, říká. Nová studie však naznačuje, že tyto náklady by mohly být sníženy, když „nepožádáme někoho výslovně, aby na nás lhal, ale pouze je v tomto směru ponořil.“ To může být zejména pravdivé, když je tento „někdo“ stroj.
Je čas postavit se za vědu
Pokud se vám tento článek líbil, rád bych požádal o vaši podporu. Vědecký Američan sloužil jako obhájce vědy a průmyslu po dobu 180 let a právě teď může být nejkritičtějším okamžikem v této historii dvou století.
Byl jsem Vědecký Američan Předplatitel od svých 12 let a pomohlo to utvářet způsob, jakým se dívám na svět. Dejte mi vědět Vždy mě vzdělává a potěší a inspiruje pocit úcty pro náš obrovský, krásný vesmír. Doufám, že to také pro vás.
Pokud Přihlaste se k odběru Vědecký AmeričanPomáháte zajistit, aby naše pokrytí bylo soustředěno na smysluplný výzkum a objev; že máme zdroje na podávání zpráv o rozhodnutích, která ohrožují laboratoře po celé USA; a že podporujeme začínající i pracující vědce v době, kdy se hodnota samotné vědy příliš často nerozpoznala.
Na oplátku získáte základní zprávy, Upmasující podcastyBrilantní infografika, zpravodaje nemohu vynechatMust-Watch videa, náročné hrya nejlepší psaní a hlášení vědeckého světa. Můžete dokonce Darujte někomu předplatné.
Nikdy nebylo důležitější čas, abychom se postavili a ukázali, proč věda záleží. Doufám, že nás v této misi podpoříte.



