„Google for DNA“ umožňuje rychlé plnotextové vyhledávání obrovských genetických archivů
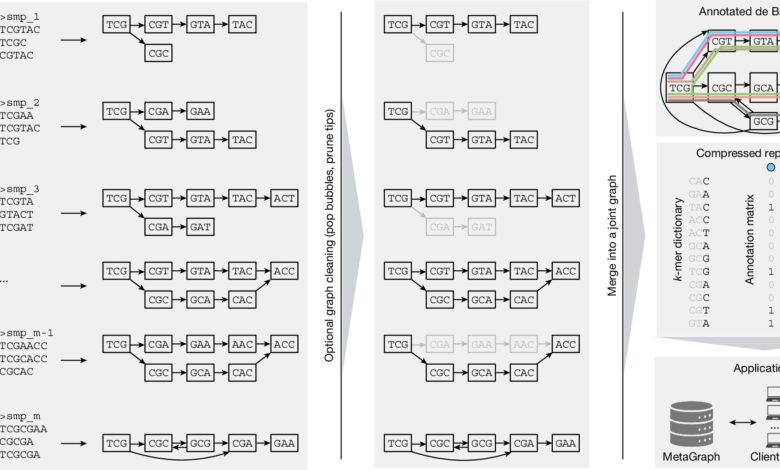
Rámec Metagraph. Kredit: Příroda (2025). Doi: 10.1038/s41586-025-09603-w
U pacientů a specifických mutací v detekovaných nádorových buňkách mohou být identifikována vzácná dědičná onemocnění – DNA sekvenování biomedicínského výzkumu sekvenování DNA před desetiletími. V posledních letech vedly nové metody sekvenování (sekvenování nové generace) k mnoha vědeckým průlomům. Například v letech 2020/2021 umožnili rychlé dekódování a globální monitorování genomu SARS-CoV-2.
Mezitím stále více a více vědců veřejně zpřístupňuje výsledky sekvenované DNA. To vedlo k vytvoření obrovských objemu dat, které jsou uloženy v centrálních databázích, jako je americký SRA (sekvenční čtení archivu) nebo evropský ENA (evropský nukleotidový archiv). Tam je uloženo asi 100 petabajtů dat – rušeně stejné množství jako veškerý text na internetu, jeden petabajte je ekvivalentem jednoho milionu gigabajtů.
K dnešnímu dni potřebovali biomedicínské vědci masivní výpočetní výkon a další zdroje, aby prohledali toto množství sekvencí DNA a porovnali je s jejich vlastními sekvencemi – vytvářeli efektivní vyhledávání v takových horách dat naprostou nemožností. Počítačoví vědci v ETH Curychu nyní tento problém vyřešili.
Full-text vyhledávání místo stahování celých datových sad
Vědci vyvinuli a metoda To výrazně zkracuje a usnadňuje toto hledání. Výzkum je publikován v časopise Příroda.
Digitální nástroj „Metagraph“ prohledává nezpracovaná data všech sekvencí DNA nebo RNA uložených v databázích – stejně jako konvenční internetový vyhledávač. Po vstupu do sekvence mají zájem o plný text do vyhledávací masky, mohou to vědci zjistit během několika sekund nebo minut, v závislosti na dotazu, kde se již objevil.
„Je to druh Google pro DNA,“ říká profesor Gunnar Rätsch, datový vědec na Katedře informatiky v ETH Curychu. Až dosud museli vědci hledat popisná metadata v databázích. Za účelem přístupu k Raw Data museli stáhnout příslušné soubory dat. Tato vyhledávání byla neúplná, časově náročná a drahá.
„Metagraph“ je z hlediska nákladů poměrně příznivý, jak vědci uvádějí ve své studii. Reprezentace všech veřejných biologických sekvencí by se vešly na několik počítačových pevných disků, zatímco větší dotazy by neměly stát více než 0,74 dolarů za megabázu.
Vzhledem k tomu, že vyhledávač DNA, který se vědci ETH vyvinuli, je také přesný a efektivní, může pomoci zrychlit Genetický výzkum-Například v případě málo prozkoumaných patogenů nebo nových pandemie.
Tímto způsobem by se tento nástroj mohl stát katalyzátorem výzkumu Antibiotická rezistence: Například identifikací rezistenčních genů nebo užitečných virů, které mohou v databázích zničit bakterie – známé jako bakteriofágy.
Komprese faktorem 300
Ve studii vědci ETH ukazují, jak funguje metagraph: nástroj indexuje data a představuje je v komprimované formě. Toho je dosaženo prostřednictvím složitých matematických grafů, které zlepšují strukturu dat – podobné programům tabulky, jako je Excel. „Matematicky řečeno, jedná se o obrovskou matici s miliony sloupců a biliony řádků,“ jak uvádí Rätsch.
Myšlenka vykreslování velkého množství prohledávání dat pomocí indexů je standardní praxe ve výzkumu informatiky.
Co je však na práci výzkumných pracovníků ETH nového, je složité propojení prvotních dat a metadat a komprese faktorem asi 300, podobně jako shrnutí knihy: již neobsahuje každé slovo, ale všechny hlavní příběhy a spojení zůstávají neporušené – ještě kompaktní, ale bez jakékoli relevantní ztráty informací.
„Posouváme limity toho, co je možné, abychom udrželi soubory dat co nejkompaktnější, aniž by ztratili nezbytné informace,“ říká Dr. André Kahles, který je stejně jako Rätsch členem biomedicínské informatické skupiny v ETH Curychu.
Na rozdíl od dalších zkoumaných masek vyhledávání DNA je přístup vědců ETH škálovatelný. To znamená, že čím větší je množství dotazovaných dat, tím méně dodatečný výpočetní výkon, který nástroj vyžaduje.
Polovina dat je již k dispozici
Výzkumníci ETH poprvé představili Metagraph v roce 2020 a od té doby jej neustále zlepšují. Nástroj je již k dispozici pro dotazy (odkaz). Poskytuje fulltextový vyhledávač pro miliony sekvenčních sad z DNA a RNA, jakož i proteiny z virů, bakterií, hub, rostlin, zvířat a lidí.
V současné době jsou indexovány necelé poloviny souborů sekvenčních dat dostupných po celém světě. Podle Gunnara Rätscha by zbytek měl následovat do konce roku. Vzhledem k tomu, že metagraph je k dispozici jako Open SourceMohlo by to být také zajímavé pro farmaceutické společnosti, které mají velké množství interních výzkumných údajů.
Kahles dokonce věří, že je možné, že vyhledávač DNA bude jednoho dne používán soukromými jedinci. „V prvních dnech ani Google nevěděl přesně, k čemu je vyhledávač dobrý. Pokud bude pokračovat rychlý vývoj v sekvenování DNA, může se stát běžnějším přesněji identifikovat vaše balkonové rostliny.“
Více informací:
Michail Karasikov a kol., Účinné a přesné vyhledávání v sekvenčních úložištích petabázu, Příroda (2025). Doi: 10.1038/s41586-025-09603-w
Citace: „Google for DNA“ umožňuje rychlé plnotextové vyhledávání obrovských genetických archivů (2025, 9. října) získané 9. října 2025 z https://medicalxpress.com/news/2025-10-google-DNA- enables-rapid-full.html
Tento dokument podléhá autorským právům. Kromě jakéhokoli spravedlivého jednání za účelem soukromého studia nebo výzkumu nemůže být žádná část bez písemného povolení reprodukována. Obsah je poskytován pouze pro informační účely.