Náročné negativní údaje pomáhají modelům AI lépe identifikovat účinné protilátky
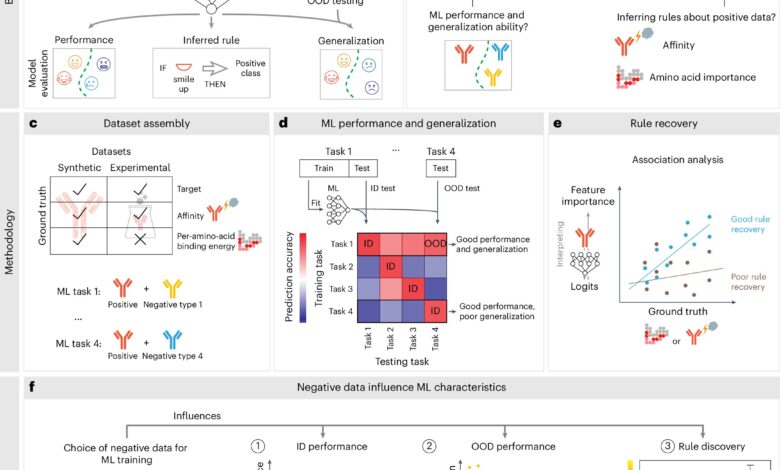
Složení údajů o tréninku určuje zobecnění ML a objev biologických pravidel. Kredit: Inteligence přírody (2025). Doi: 10.1038/s42256-025-01089-5
Představte si, že vyvíjíte protilátky-léčby přesně zaměřené na cíl, například virový protein nebo onco-marker. Testujete řadu protilátek a zjistíte, že některá práce, zatímco jiní ne.
Chtěli byste je pokračovat v úpravě a zjistit, zda je můžete ještě zlepšit. Nechcete však ztrácet čas testováním těch, které rozhodně nebudou fungovat. Pouze testovat protilátky To by mohlo fungovat, musíte oddělit ty protilátky, které se nevážejí na váš cíl, než se přesunete na nákladné a časově náročné experimenty.
Jedním ze způsobů, jak toho dosáhnout, je trénovat a výpočetní model které vás mohou v tomto procesu podpořit. Dnes, strojové učení Modely již pomáhají experimentálním vědcům zúžit jejich hledání.
„Navíc, modely strojového učení, jakmile jsou uvedeny data, se mohou dozvědět, co dělá protilátkovou vazbu – to, co funkce odlišuje, odlišuje se od těch, která ne. Bez takových modelů to není vůbec zřejmé, protože leží za sebou lidské vnímání a intuice, “říká Aygul Minnegalieva, kandidát Ph.D. na University of Oslo.
Zkoumá, jak nejlépe trénovat modely AI v laboratoři Greiff. Minnegalieva a kolegové nedávno zveřejnili a studie na to v Inteligence přírody.
„Ne všechny modely strojového učení to však budou dělat správně. Pouze pokud jsou modely vyškoleny se správnými údaji, můžeme je použít k pochopení biologických determinantů. Například to, co dělá protilátku pořadačem,“ vysvětluje.
„Jedním přístupem k dosažení tohoto cíle je představit modely příklady správných i nesprávných odpovědí ohledně toho, co chceme, aby rozpoznali,“ vysvětluje Ph.D. kandidát.
Takové nesprávné příklady nebo chyby jsou označovány jako negativní údaje, zatímco správné příklady jsou klasifikovány jako pozitivní data.
Chyby musí představovat výzvu, aby modely rozpoznaly. V poslední studii Minnegalieva a její kolegové zjistili, že negativní údaje, kterým jsou modely vystaveny, musí být dostatečně náročné.
„Musíme ukázat nesprávné příklady modelů, které se velmi podobají správným.
Konkrétně vědci prezentovali modely jako negativní data s protilátkami, které se stále vážou na cílové proteiny, například u viru, ale dělají tak suboptimálně.
„Tímto způsobem modely zlepšily svou schopnost přesně rozeznat protilátky, které by byly účinné v boji proti patogenu od těch, které by to nebylo,“ vysvětluje.
Nejdůležitější je, že tato metoda umožnila modelům zachytit základní sekvenční determinanty v protilátkách, které jim pomáhají vázat se na protein v patogenu.
„Tyto determinanty dávaly větší biologický smysl,“ uvádí Minnegalieva. „Modely se v podstatě zlepšily v úvahu.“
Zrychlení vývoje protilátek a léků AI
Strojové učení se stále více používá ve vývoji nových léčivých přípravků, což vědcům umožňuje snížit počet požadovaných experimentálních testů.
„Můžeme snížit počet chyb při vývoji nových kandidátů protilátek nebo léčiv pro cílení na patogeny nebo rakovinu,“ říká Minnegalieva. „Modely, které používáme, musí být přesné a spolehlivé. Musí skutečně pochopit, na čem záleží z biologického hlediska. Teprve pak můžeme dělat zvukové předpovědi a ušetřit čas.“
Nová studie nastiňuje, jak mohou být modely vyškoleny, aby lépe splňovaly tyto požadavky.
Ačkoli studie se konkrétně zaměřila na protilátky, výsledky mohou být široce zobecněny na různých oborech, kde je aplikováno strojové učení.
„Pole, jako je modelování jazyka, návrh proteinů a predikce molekulárních vlastností, také závisí na vzorkování negativních dat. Všechny tyto oblasti čelí riziku, že modely přijímají zkratky, pokud jsou negativní příklady příliš zjednodušené,“ uzavírá Minnegalieva.
Profesor Victor Greiff, vedoucí laboratoře Greiff, také zdůrazňuje relevanci a potenciální dopad studie. „Naše práce ukazuje, že kurátor dat není krokem předběžného zpracování, je to vědecká volba, která kóduje předpoklady a určuje, co strojové učení může objevit.
„Pro imunologii, objev drogA mimo něj může být pečlivý návrh datových sad klíčem k vytváření modelů strojového učení, které zobecňují a odhalují skutečné biologické principy, “říká Greiff.
Více informací:
Eugen Ursu a kol., Složení dat tréninku určuje zobecnění strojového učení a objevování biologických pravidel, Inteligence přírody (2025). Doi: 10.1038/s42256-025-01089-5
Wesley Ta a kol., Důležitost negativních údajů o tréninku pro robustní predikci vazby protilátky, Inteligence přírody (2025). Doi: 10.1038/s42256-025-01080-0
Poskytnuto
University of Oslo
Citace: Výzva negativních údajů pomáhá modelům AI lépe identifikovat účinné protilátky (2025, 15. září) získané 16. září 2025 z https://medicalxpress.com/news/2025-09-negative-ai-efektivní-ntibodies.html
Tento dokument podléhá autorským právům. Kromě jakéhokoli spravedlivého jednání za účelem soukromého studia nebo výzkumu nemůže být žádná část bez písemného povolení reprodukována. Obsah je poskytován pouze pro informační účely.